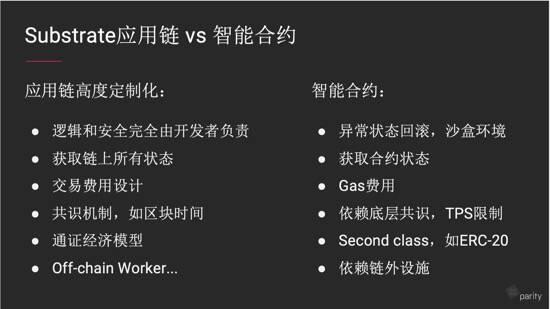
主页 > imtoken苹果app > 为什么 BSV 链上的应用程序运行速度比 ETH 上的快数千倍
为什么 BSV 链上的应用程序运行速度比 ETH 上的快数千倍
BSV什么时候变得这么厉害了? BTC做不到的,ETH做不好的,Filecoin在做的,他们做不到的,BSV都能做! ? 这篇文章通俗易懂,非专业人士给你解释清楚。
目前 BSV 上有 427 个应用程序。 如果你不相信 BSV 公链的效率,你可以自己体验一下。
1. 以太坊的链上计算模型
众所周知,以太坊的设计目标是成为“世界计算机”(World Computer),可以进行交易以外的计算。 关于这一点,人们经常打一个这样的比喻——与以太坊的计算能力相比,比特币就像一个计算器,只有一些预定义的简单操作。
那么以太坊是如何实现链上通用计算的呢?
在以太坊上,人们使用(不太成熟的)Solidity 来实现计算逻辑,以确保与以太坊共识的兼容性。 写好的代码通过交易提交到链上,成为所谓的“智能合约”。 当这个合约被执行时(矿工将其写入一个区块),所有节点都需要执行并验证这个合约(以确保有效性和一致性)。 ETH通过引入Gas来定义算力与手续费的关系。
显然,这个想法的可扩展性是有限的。
整个网络的处理能力取决于网络中最弱的节点。 (此处“GL-Note”存疑,没有验证能力或验证效率低的节点实际上不会影响全网的整体进度)
主网上线后的所有计算都累积在整个区块链上,任何新加入网络的节点都需要从一开始就同步并(仅出于历史原因)完整地执行所有这些计算。
以太坊节点同步速度慢,计算量巨大。 全网算力基本达到瓶颈,可执行操作的范围受到很大限制。 在这种情况下,无论是所谓的“链上超级计算机”,还是千兆级别的数据处理,目前都是不现实的。 现有的解决方案有3种:1)将复杂的操作从合约转移到DApps的具体实现,2)寻找像Plasma这样的侧链,3)将操作和结果隐藏在状态通道(State Channels,类似于闪电网络)支付通道)。
即使存在这些问题,以“智能合约”形式实现的链上操作仍然成为了事实上的主流方式。 后来的一些区块链试图模仿和改进,比如切换到成熟的编程语言、多链协作、其他共识算法(DPOS)等。 (“GL-Note”在同步执行计算方面似乎没有太大变化)
2. BSV的链上运行模式
与以太坊“把区块链当作CPU”不同,BSV的思路更倾向于把区块链当作数据库和操作系统。
_unwriter 在比特币现金上开发 BitDB 时,他应该是第一个“真正”把区块链当作数据库使用的人。 后来分叉的时候,_unwriter选择了BSV的路线,并留下了一篇有价值的博客:
比特币现金实验的解决方案
【中】(黄肉肉@微博)深度解析比特币现金实验
Craig Wright 发布 Metanet 后,_unwriter 立即发布了一系列相关工具。 这些工具的共同设计基础是将区块链作为数据库和操作系统(进一步来说,作为某种意义上的互联网)来使用。
BitDB将数据库去中心化,将区块链写入Mongodb,让所有操作更容易检索。
Genesis为BSV专属bitdb节点(2018年11月分叉后)
Babel 是自定义的 bitdb 节点,只关心 OP_RETURN 中存储的数据,不关心典型的交易
Planaria (amoeba) 更通用的BitDB,支持自由定制规则,可以在链上存储和检索任何形式的数据
BottleBitcoin Browser是一个自定义的bitdb节点,一个比特币浏览器(注意这是一个真正的浏览器,不是区块浏览器),使用B://和C://来定位所有资源,真正的serverless,完全容纳在比特币内部区块链的边界。
BitComBitcoin Computer仿Unix文件系统,使用Bitquery加载目录,方便二次应用协议定义
DataPay是一个轻量级的js库,最简洁的带数据发送tx的库,没有之一(MoneyButton和Bitpay都在用)。
Babel - 用于纯数据比特币应用程序的 BitDB 节点
(hqm@知识) Bitcoin SV 开发理念 - Amoeba Framework
(hqm@知话)BSV涡虫框架技术总结一节点搭建
(hqm@知识)BSV涡虫框架技术总结2 Bitquery
简单来说,Planaria可以用来存储和检索(以数据库的形式),DataPay可以用来写,BitCom可以用来定义访问协议(类似文档扩展的作用),Bottle用来连接不同类型的数据和资源呈现给用户。 (当“GL-Note”连在一起的时候,这已经是真正成型的冯·诺依曼架构了)
2019 年 1 月,nChain 开采的一个区块中包含一个 100KB 的 OP_RETURN 交易,此后,220 字节的限制被打破。 几个小时后,_unwriter 发布了一个网站,以无服务器网站的形式展示了爱丽丝梦游仙境中的一章。 (《GL-Note》这里需要用到ZeroNet,但是和爱丽丝梦游仙境相比,ZeroNet只是一个比特币+Torrent的壳)
3、新模式的重点是什么?
从那时起,出现了一种新的链上计算模型。 操作本身是链下的。 只有指令(如一段脚本代码或库)作为“文件”存储在链上。
区块链原来不是CPU,而是文件系统。
当用户在链上进行操作时,实际上只是在本地运行需要的操作(比如在浏览器中执行一段js代码)。 由于其他节点不关心执行过程,相应的操作在链下进行,只有产生有意义的结果才上传到链上。 最终显示的结果要么是有意义的交易(形式为tx),要么是有意义的数据(形式为OP_RETURN)。
使用这台超级计算机,你可以使用任何语言和任何库(已经存在于链上),而不用担心“合约”和共识的兼容性,或者(过度)担心容量和大小。 数据和脚本在链上,而操作在链下。 这是ETH和BSV在模型上最大的区别。
但这样一来,人们自然会问,如果所谓的“区块链计算模型”不发生在链上,那么这个模型还有什么意义呢? 如果关键操作不是所有节点同步执行,谁来保证操作有效、合法、符合预期? 与旧的数据库和互联网相比,这有什么优势?
关键是以下两点是不可变的和认证的:
链上运行保证了执行过程可以在需要的时候随时被验证。 (按需验证)
结果上链,保证了执行结果可以在需要的时候随时验证。 (按需验证)

「GL-Note」 无论代码是否开源,给定程序的执行过程和运行(protocol/spec)都被记录在案,全网见证; 无论数据是否加密,都不会再主动或被动地“丢失”。 与自己维护服务器相比,这两种方法都更健壮且成本更低。
《GL-Note》以游戏为例:
比如我现在正在写一个游戏,我把游戏的所有代码上传到一个tx(tx_sourcecode)。 本游戏链上产生的所有tx_gamedata都与tx_sourcecode关联。 矿工只是无意识地提交 tx_sourcecode 和 tx_gamedata(只要他们支付足够的矿工费)。 注意:对于我的游戏,矿工不是利益相关者。 游戏是否盈利与它没有直接关系。 为了维持游戏的正常运行,游戏运营者有很强的动机从源代码->游戏数据运行计算。 对此行为有疑虑的可以使用tx_sourcecode自行运行逻辑验证。
和朋友讨论的时候,朋友提到,即使同一段lua代码在不同的机器、不同的运行环境下是不同的,如何保证结果是可验证的? 在 ETH 中不会有这样的问题,因为需要立即就结果达成一致。
而且我认为这实际上并不需要矿工来保证,因为他们不是利益相关者。 游戏行为不一致,受损的是游戏厂商。 矿工们基本上是无动于衷的。 只要你支付足够的交易手续费,我会帮你打包上传到链上。 没有义务“验证所有逻辑一致性”(就像矿工没有“验证链上的所有数据是遵守当地法律法规的义务一样,同理)。游戏和应用开发者关心这一点。此外, lua/python等语言的设计目的就是在不同的环境下尽可能给出一致的执行结果,如果做不到这一点,自然会有更多定义明确的语言来填补这个需求。在实际中产品,有限的运行时间(沙箱)应该就足够了。
4. ETH与BSV模型对比
ETH 强制上链执行合约,本质上是对“矿工验证交易”的过程进行了概括和扩展。 客户端发起一笔交易(与某个合约相关),本质上相当于触发了一个全网执行的动作。
另一方面,BSV 走了一条截然不同的道路。 当一个网站以serverless模式运行时,客户端可以随时修改和操作某一部分数据,除了这部分数据因此保存在链上,其他矿工和用户不关心网站上的这部分数据基本都是Feelingless。
ETH 的合约在满足一定条件时可以主动创建交易,而 BSV 链只有代码和结果,只能被动接收用户发起的交易。 ("GL-Note" 但在实践中,问题不大,只需要使用bitdb监控特定的事件,触发交易以太坊计算器,就可以达到同样的效果。注:这个监控和响应的代码逻辑是也在链上,所以也是可验证的)
这里,原文提到了BSV未来操作代码的恢复和扩展,以及可能的图灵完备性。 这些以后再说,暂时不多说。
5.(使用新模型)构建去中心化超级计算

一个思想实验:我们现在要建造两台超级计算机,分别位于ETH和BSV上,需要运行一个60MB的程序来计算1GB的气候数据。
先看看以太坊,
很难在以太坊上存储 1GB 的数据,这几乎是一周的数据量。 60MB的程序放在上面比较容易,但是也会需要大量的脚本改动,耗费大量的Gas,还可能存在安全隐患。 那么,考虑到实际操作,从计算能力的角度来看,这样的计算可能会消耗大量的Gas。
人们意识到,与其在以太坊上构建超算,不如在链上构建超算市场(超算市场)更有意义。 Golem 正是这样做的——使用智能合约来满足去中心化计算能力交易(supercomputer power)的需求。 (“GL-Note”与 NiceHash 没有太大区别,只是它更通用一些)
让我们再看看比特币 SV,
首先,1GB并不是一个很大的数据量。 Ryan X. Charles 曾经上传过 1.4GB 的图片。 然后,有一个 60MB 的指令序列,它们都被发送到链上。 这时,借助一个链上交易网站,可以将提供算力的人和需要算力的人匹配起来。 这样,区块链就变成了一个共享的文件系统。
(“GL-Note”好像绕了点弯路。说实话,从实用的角度来说,运营商直接用算力支撑计算需求,然后卖服务更容易。毕竟SaaS还是比dex的门槛低很多。少)
6.一些个人想法
《GL-Note》原文最后一段是作者的一些杂感,就不逐句抄袭了。 这一段是我加的,是我形成这篇文章时的一些个人感慨。
上面对ETH和BSV做了很多比较,这里我也做个比较。 在 ETH 网络中,矿工、节点和其他参与者之间的关系复杂且定义不明确,整个网络缺乏自发向更好方向演进的能力。 在BSV区块链网络中,矿工、服务提供者、服务参与者从整个架构设计的角度是明确界定的,本质上只关心自身利益。
让我们扩大它。 比如矿工,所有的经营动机都只是为了从长远来看不断提高自己的利润率。 至于算计,喜欢谁算谁。 我把你的数据存储在链上,这只是我打包赚钱的天然副产品。 再比如,一个服务商把区块链当作商品,我支付矿工费,得到一个公共账本+永不丢失的数据+透明可验证的舆论效果。 这样算下来以太坊计算器,比在阿里云上租服务器更划算。 省钱省事比较划算(初期可能比较简单,商业云上的工具没有那么多,当然这是机会)。 另一个例子是服务用户。 将区块链上的 Twetch 与中心化的微博进行比较,根本没有可比性。 删帖封号,更何况大数据侵犯隐私。 持有私钥,您对自己的数据有足够的控制权。 说句题外话,也许在未来的某一天,一个人的数据可能比这个人本身更有价值。
我相信关于链上计算的讨论才刚刚开始。 现在的情况其实很像DOS时代的PC行业。 _unwriter实现的一系列工具,就像在DOS下一样,我们可以简单的通过基本手段控制PC的硬件资源。 然而,从工具到操作系统,这种可操作性的快速增长反过来又迫使当时的硬件标准化,直到只剩下Win-tel。 这其中有着深刻的历史必然性。 同理,区块链从无数不为人知的创新项目迅速汇聚成最具扩展性和可操作性的链条,“书同文,车同轨”,才有生存的机会,创造更长期的价值,更深刻地改变人类社会。



